pytorch入门
学习自b站up我是土堆的视频 https://www.bilibili.com/video/BV1hE411t7RN 代码仓库:https://github.com/caolib/pytorch_learn.git pytorch中文教程:https://docs.pytorch.ac.cn/tutorials/beginner/basics/intro.html
1.安装
1.1 安装uv
uv 是由 Astral 公司开发的一款 Rust 编写的 Python 包管理器和环境管理器,它的主要目标是提供比现有工具快 10-100 倍的性能,同时保持简单直观的用户体验uv 可以替代 pip、virtualenv、pip-tools 等工具,提供依赖管理、虚拟环境创建、Python 版本管理等一站式服务
irm https://astral.sh/uv/install.ps1 | iex1.2 安装python
uv python install 3.131.3 创建虚拟环境
新建一个文件夹
pytorch_learn作为项目目录创建虚拟环境并激活
shuv venv ./.venv/Scripts/activate
1.4 安装pytorch
如果电脑有独立显卡的话,打开一个控制台输入nvidia-smi,会有类似下面输出,记住这里的CUDA Version: 12.9
|> nvidia-smi
Sat Sep 20 15:07:46 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 577.00 Driver Version: 577.00 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+前往PyTorch官网,往下滑找到这个图片,注意CUDA版本和自己显卡对应,选好后复制命令
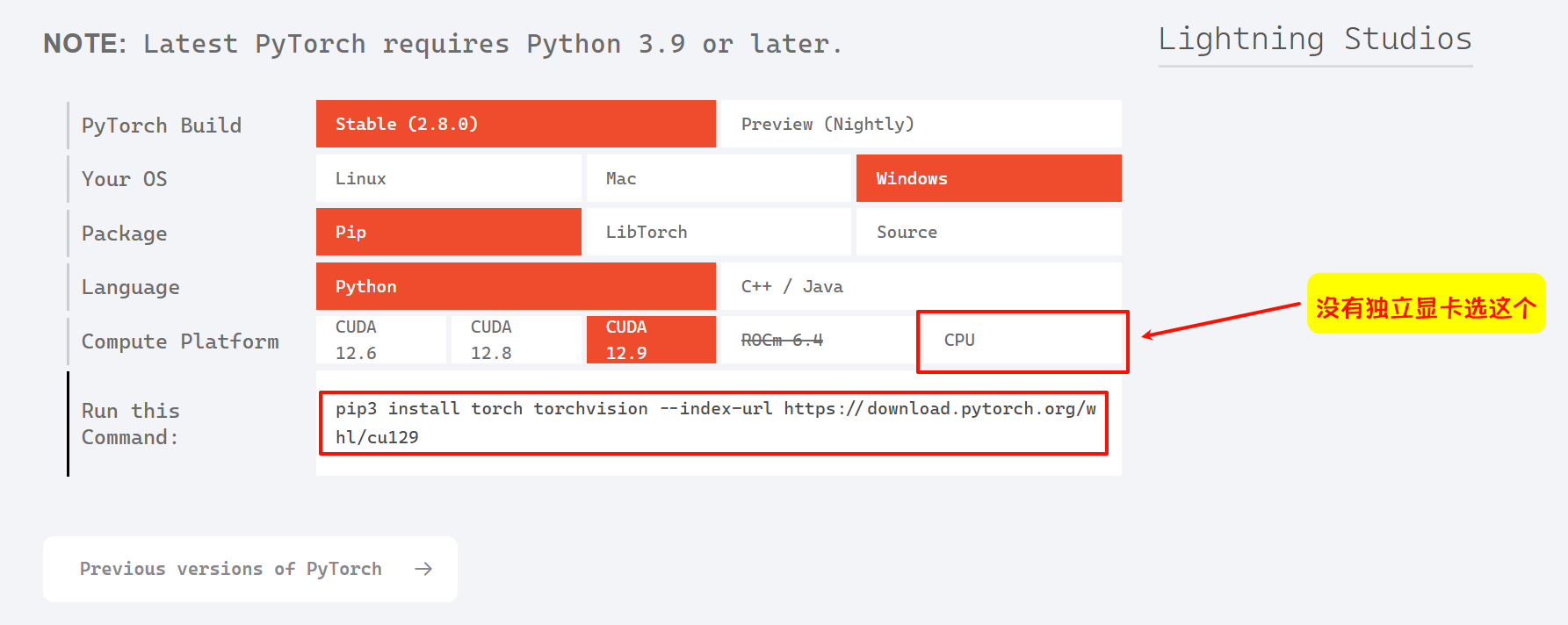
回到项目文件夹下,先激活虚拟环境
./.venv/Scripts/activate然后安装pytorch,注意不是直接粘贴,稍微修改一下,pip3去掉3,在前面加上uv,然后等待下载完成就行了
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu129安装完成后可以检查看看是否安装完成
python -c "import torch; print('PyTorch version:', torch.__version__); print('CUDA available:', torch.cuda.is_available()); print('CUDA version:', torch.version.cuda); print('Number of GPUs:', torch.cuda.device_count()); print('Current GPU:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'None')"输出大概类似下面,如果有显卡的话第二行显示就是True
PyTorch version: 2.8.0+cu129
CUDA available: True
CUDA version: 12.9
Number of GPUs: 1
Current GPU: NVIDIA GeForce RTX 5060 Laptop GPU1.5 在IDEA中使用
可能有人会问为什么不用PyCharm,其实体验都差不多,因为我电脑上已经有了IDEA,我也懒得再下载一个,如果你也使用IDEA的话可以先安装一个python的插件
使用IDEA打开项目目录后,首先要设置项目的python解释器环境,依次点击文件->项目结构->SDK->从磁盘添加
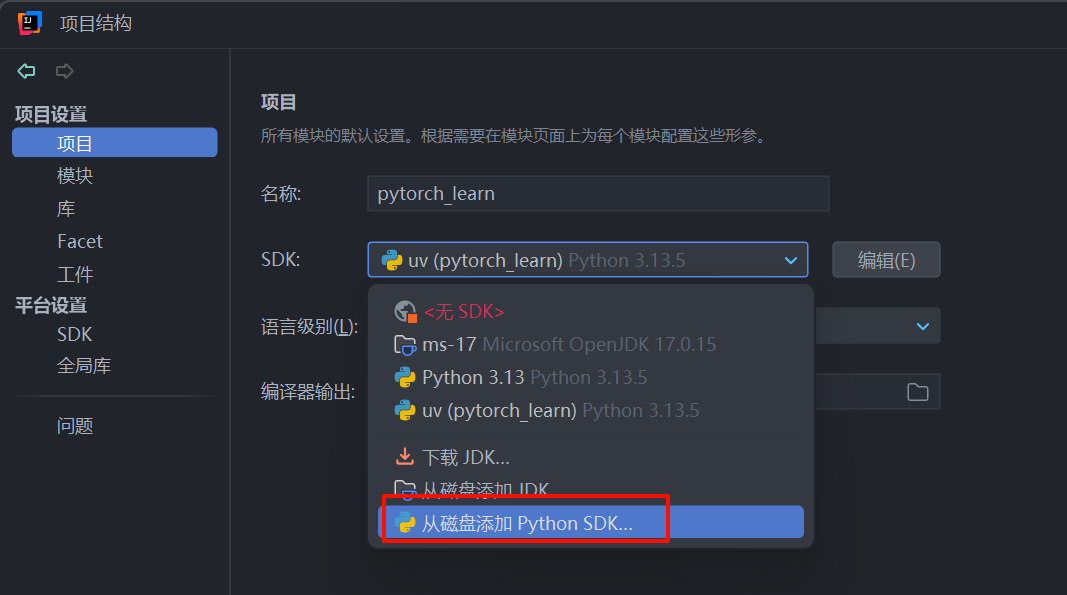
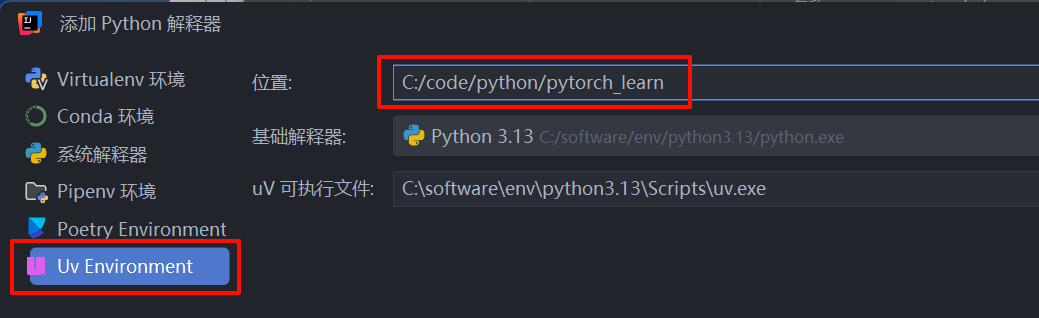
因为我们使用uv,所以选最后一个,然后选择位置就是当前项目的目录
2.Dataset
NOTE
Dataset 是 PyTorch 数据加载的核心抽象类,定义在 torch.utils.data 模块中。它提供了一种统一、面向对象的方式来管理和访问你的数据,尤其适用于自定义数据集、预处理和与 DataLoader 协同使用。
自定义数据集对象
import os
from PIL import Image
from torch.utils.data import Dataset
class MyData(Dataset):
# 构造函数
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path_list = os.listdir(self.path)
# 获取一个图片
def __getitem__(self, index):
img_name = self.img_path_list[index]
img_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_path)
label = self.label_dir
return img, label
# 获取图片个数
def __len__(self):
return len(self.img_path_list)读取数据集对象,在对应的文件夹生成txt文件
import os.path
from src.dataset.read_data import MyData
root_dir = '../../dataset/train'
ants_label = 'ants'
bees_label = 'bees'
ants_dataset = MyData(root_dir, ants_label)
bees_dataset = MyData(root_dir, bees_label)
def gentxt(dataset, label):
for i in dataset.img_path_list:
name = i.split('.')[0] + '.txt'
with open(os.path.join(root_dir, label + '_label', name, ), 'w', encoding='utf-8') as f:
f.write(label)
gentxt(ants_dataset, ants_label)
gentxt(ants_dataset, bees_label)3.tensorboard
3.1 简介
TensorBoard 是 TensorFlow 官方提供的一个可视化工具,主要用于帮助用户理解、调试和优化他们的机器学习模型通过 TensorBoard,用户可以直观地观察训练过程中模型的各种指标、结构和数据流,辅助模型开发和性能分析
主要功能包括:
- 可视化损失和准确率等指标 可以实时绘制训练和测试过程中的loss、accuracy等曲线,便于分析模型的训练动态
- 可视化模型结构 显示神经网络的计算图结构,理解各层之间的连接关系,方便调试
- 参数分布与直方图 观察权重、偏置等参数的分布变化,可分析梯度消失/爆炸等问题
- 嵌入可视化 支持用T-SNE、PCA等方法将高维向量(如词向量、特征向量)降维,直观分析数据分布和聚类效果
- 图像、音频等数据的可视化 可展示训练和测试过程中的图片、音频、文本等样本,帮助评估模型效果
3.2 使用
首先安装tensorboard
uv pip install tensorboard使用tensorboard画一条曲线 $y=x^2$ ,运行后在logs文件夹生成数据文件
import os.path
from torch.utils.tensorboard import SummaryWriter
from src.path import target_dir
path = os.path.join(target_dir, 'logs') # 数据文件路径
writer = SummaryWriter(path)
# 向tensorboard添加标量,绘制成一条曲线
for i in range(100):
writer.add_scalar('y=x^2', i * i, i)
writer.close()
# 使用命令启动tensorboard,路径和上面生成的路径匹配 tensorboard.exe --logdir=C:/code/python/pytorch_learn\\target\\logs启动tensorboard,路径和上面的logs生成路径对应,默认运行在6006端口(可以使用--port=选项修改为其他端口),打开http://localhost:6006
tensorboard.exe --logdir=C:/code/python/pytorch_learn\\target\\logs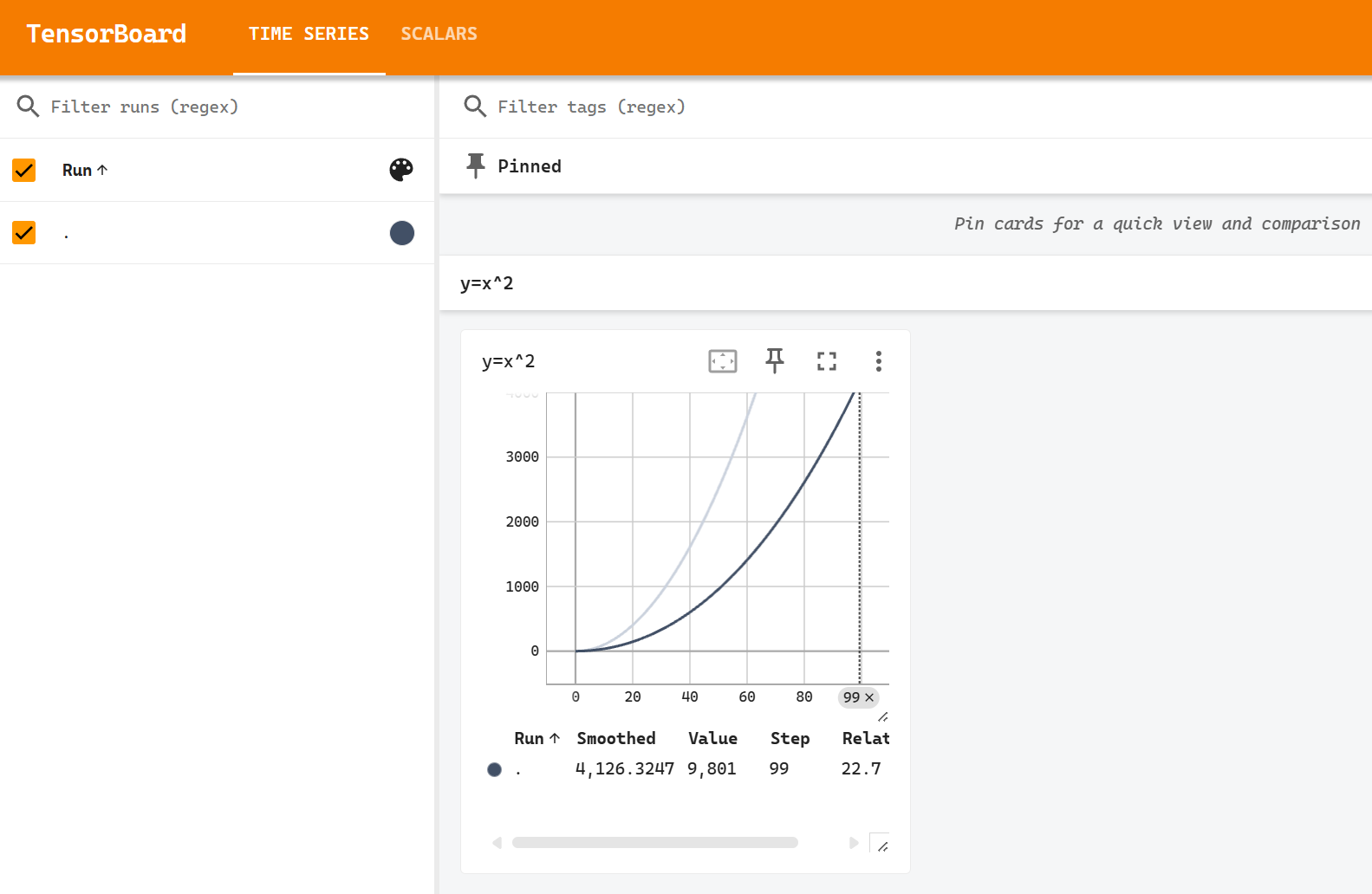
也可以添加图片
from os.path import join
import numpy as np
from PIL import Image
from src.path import ants_dir
from src.tensorboard.tb import writer
img_path = join(ants_dir, '0013035.jpg')
img_pil = Image.open(img_path)
img = np.array(img_pil)
print(img.shape)
writer.add_image('image', img, 1, dataformats="HWC")
writer.close()4.transforms
transforms 是 PyTorch 中专门用于数据预处理和增强(主要用于计算机视觉任务)的一组工具,常见于 torchvision.transforms 模块它的主要作用是对输入的数据(如图片)进行各种变换,使其适合于神经网络的输入并提升模型的鲁棒性和泛化能力
常见功能和作用
- 格式转换:将PIL图片或NumPy数组转换为PyTorch的
Tensor,例如:transforms.ToTensor() - 归一化:将像素值缩放到特定范围(通常是[0,1]或均值为0,方差为1),如:
transforms.Normalize(mean, std) - 数据增强
- 在训练时对原始图片进行随机处理,以增加数据多样性,减缓过拟合例如:
- 随机裁剪:
transforms.RandomCrop() - 随机水平翻转:
transforms.RandomHorizontalFlip() - 随机旋转:
transforms.RandomRotation() - 色彩调整:
transforms.ColorJitter()
- 随机裁剪:
- 在训练时对原始图片进行随机处理,以增加数据多样性,减缓过拟合例如:
- 尺寸调整:对图片缩放、裁剪,使其满足模型输入要求,如:
transforms.Resize()、transforms.CenterCrop()
4.1 ToTensor
将PIL图片对象转换为ToTensor对象,tensor即张量
from os.path import join
from PIL import Image
from torchvision import transforms
from src.path import ants_dir
from src.tensorboard.tb import writer
# totensor使用
# 1.创建PIL图片对象
img_path = join(ants_dir, '0013035.jpg')
img = Image.open(img_path)
# 2.创建ToTensor对象
to_tensor = transforms.ToTensor()
# 3.将图片转换为ToTensor对象
img_tensor = to_tensor.__call__(img)
# 4.添加图片到tensorboard
writer.add_image("tensor_img", img_tensor, 1)4.2 normalize
Normalize 会对图片每个通道(如RGB的R、G、B)分别进行线性变换:
$$ output[channel] = (input[channel] - mean[channel]) / std[channel]
$$
在下面代码中,mean=[1,3,9],std=[4,7,9],所以每个通道的像素值都会被减去对应的均值,再除以对应的标准差 作用:
- 归一化可以让不同通道的像素值分布到相似的范围,有助于加快神经网络的收敛速度,提高训练稳定性
- 避免某些通道的数值过大或过小,导致模型训练时某些权重主导或梯度消失
NOTE
总结:Normalize 让图片的每个通道数据分布更均匀,有利于深度学习模型的训练和收敛
import torchvision.transforms
from src.tensorboard.tb import writer
from src.transforms.totensor import img_tensor
# 定义归一化变换,指定均值和标准差
transnorm = torchvision.transforms.Normalize([1, 3, 9], [4, 7, 9])
# 对 img_tensor 应用归一化
img_norm = transnorm(img_tensor)
# 分别打印归一化前、后的第一个像素值
print(img_tensor[0][0][0])
print(img_norm[0][0][0])
# 将归一化后的图像写入 TensorBoard
writer.add_image("normalize", img_tensor, 1)
writer.add_image("normalize", img_norm, 2)
writer.close()4.3 Resize
说明:
- Resize 用于改变图像的空间尺寸(宽、高)
- 当传入一个整数 size 时,短边被缩放到 size,且会保持原始宽高比;
- 当传入一个二元组 (h, w) 时,图像会被缩放为精确的 (高度, 宽度),这会改变长宽比(可能导致拉伸/压缩)
- Resize 使用插值来计算新像素(默认是双线性/双立方插值,取决于 torchvision 版本),这会轻微改变像素值(与简单的裁剪不同)
- Resize 在不同 torchvision 版本上对输入类型的支持不同为了兼容且可预测,我们先把张量转换为 PIL Image,执行 Resize,然后再转换回张量
ToTensor会把 PIL Image 转为范围 [0.0, 1.0] 的浮点张量,形状为 (C, H, W),适合 writer.add_image
from torchvision import transforms
from src.tensorboard.tb import writer
from src.transforms.totensor import img_tensor
img_resize = transforms.Resize((512, 512))(img_tensor)
writer.add_image('img_resize', img_resize, 1)
writer.close()4.4 Compose
torchvision.transforms.Compose 是一个工具,用于将多个图像变换(transforms)按顺序组合成一个整体的变换流程这样你可以把一系列预处理操作(如裁剪、缩放、归一化、转张量等)组织在一起,方便地应用到每一张图片上,实际就是用于定义一个变换的组合,比如我定义一个变换A,先转换图片类型,然后改变尺寸等操作
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
# 定义一个变换序列:先缩放到 256x256,再转为张量,再归一化
transform = Compose([
Resize((256, 256)), # 缩放图片
ToTensor(), # 转为 torch.Tensor
Normalize(mean=[0.5,0.5,0.5], std=[0.5,0.5,0.5]) # 归一化
])
# 应用到图片
from PIL import Image
img = Image.open('example.jpg')
img_tensor = transform(img)4.5 数据集的使用
pytorch官方提供了很多数据集,可以直接在代码中使用,下面是CIFAR10数据集的使用
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, ToTensor
from src.path import dataset_dir
from src.tensorboard.tb import writer
# 定义数据预处理流程:Compose 串联多个变换,这里只包含 ToTensor(将PIL图片转为torch张量,值域[0,1])
ds_transform = Compose([
ToTensor(),
# 可以在这里继续添加其他变换,如Normalize、RandomCrop等
])
# 加载CIFAR10训练集和测试集,如果本地没有,则自动下载到指定目录,并应用上面定义的transform
train_set = CIFAR10(root=dataset_dir, transform=ds_transform, train=True, download=True)
test_set = CIFAR10(root=dataset_dir, transform=ds_transform, train=False, download=True)
# 遍历前10张训练集图片,将其写入TensorBoard,便于可视化数据预处理结果
for i in range(10):
img, _ = train_set[i] # img为torch.Tensor格式,适合add_image
writer.add_image('dataset', img, i)
writer.close()5.DataLoader
dataloader 是 PyTorch 中用于批量加载数据的工具。它可以将数据集分成小批量(batch),并支持多线程加载、数据打乱(shuffle)、丢弃最后不足一批的数据(drop_last)等功能。常用于训练和测试时高效地读取数据。
from torch.utils.data import DataLoader
from src.tensorboard.tb import writer
from src.transforms.dataset_op import test_set
'''
batch_size=64 每次从数据集中取64个数据然后打包
shuffle=True 每次取数据前先打乱数据
drop_last=True 最后一组如果不够64个直接舍弃
'''
test_loader = DataLoader(test_set, batch_size=64, shuffle=True, drop_last=True)
for index, data in enumerate(test_loader):
imgs, targets = data
writer.add_image("dataloader", imgs, index, dataformats='NCHW')
writer.close()